
Is the One-Body Problem Killing Your Growth KPIs?
Is the One-Body Problem Killing Your Growth KPIs?
Nerd out with me about using just "one-body" in research versus a much more stable "two-"


Growth has been a grind.
And not the typical it’s-summer-and-everyone’s-distracted grind, but the kind of grind that makes you think, “Hmmm… something doesn’t seem quite right. Is it supposed to be this hard?”
Your first thought is maybe it’s just you. You’ve been working hard, after all. This year has also been weird for everyone.
But you can’t help but wonder if you’re missing something.
So you do some digging through all of your analytics platforms and data.
You pop open a few OKR dashboards and old spreadsheets. Start exporting some reports from a few platforms to see if there’s anything you missed.
That’s when you stumble upon it — something you hadn’t quite noticed before, but it’s there: your activation rates have been steadily declining for the last 6 months.
In fact, they haven’t really been above a certain percentage for a long time — maybe more than a year.
Now you’re cooking. You know what to explore now!
You start watching some in-app recordings of new users to see what’s going on.
Generally things seem…. okay? But there’s definitely context missing, and you already know that quantitative can’t tell you why things are happening, but only what is happening.
While there are some obvious patterns, you’re still not sure of a few things:
Were these people even qualified?
What brought them to the app in the first place?
What were they hoping to use it for?
Did they compare us to anyone else?
Did they choose something else over us? If so, what?
You consider running a survey at first but decide against it because you know that raw voice of customer will be far more effective than a high-level survey. Perhaps you’ll run one after you’ve conducted some initial interviews to better inform your question-strategy.
Plus, you know activation work of any kind requires a deep understanding of the details in the buyer journey, and surveys just won’t go deep enough.
So you start poking through the user database, and select a few folks who seem like ideal candidates. Your strategy is to interview a diverse pool of new users who never became customers, but also didn’t seem to really hit the moment of activation — the North Star KPI that would indicate they’d likely become a customer based on their usage.
You even selected a diverse range of industries because based on their email address, you can kinda tell what companies these people work for.
And then, you fire off the interview invitation email and wait for the first cohort to reply back.
This, dear reader, is what I call the “One-Body Problem.”
The One-Body Problem
Here’s the thing: if you could relate with the above, then you did everything right.
Leveraging qualitative insights in the first place for understanding something as complex as activation in SaaS was already an A+ move.
There’s still a lack of understanding around how to leverage research and insights to improve critical and fundamentals SaaS growth KPIs like activation. A great example is from the #buildinpublic community on Twitter where a founder asked how to troubleshoot his freemium conversion rates.
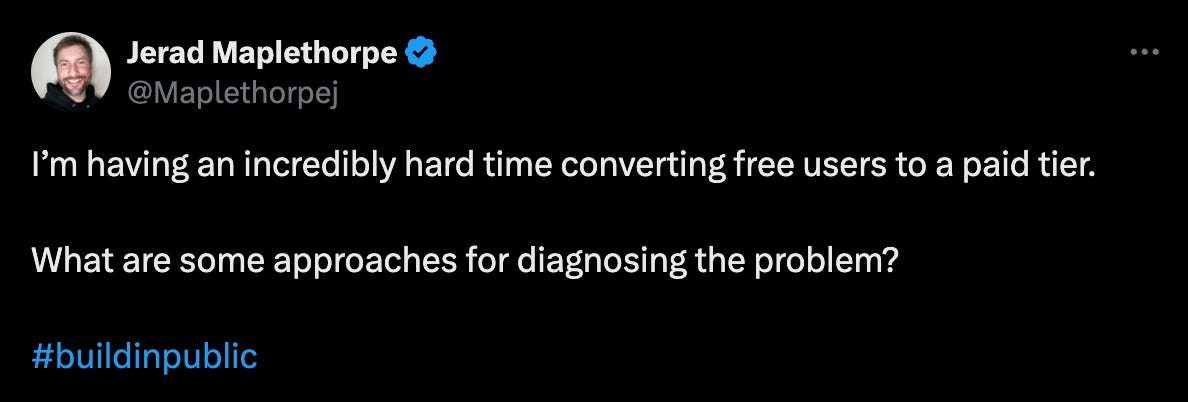
Now is freemium the right model for his business? Maybe.
But model aside, only one person out of the 59 replies (1.9%) suggested to conduct user research and specifically talk to users about why they don’t become a paid customer.
If you count my response, it bumps it up to 3%.
Even with talking to users who don’t become a customer, we’re confronted with the “One-Body Problem.”
The One-Body Problem is simple: we’re leveraging insights from only one cohort of users without considering their foil or mirror cohort.
If you remember science class, you know in an experiment, we have our variable — the changeable thing that produced an outcome we’re trying to understand — and our control — the thing we’re going to compare the variable to.
The control is our constant; we understand why it produced a certain outcome and can easily compare and contrast against it.
The variable, however, is what we don’t necessarily understand or can predict, but there is a change that has occurred to the variable and produced an outcome that we’d like to analyze.
For example, if we want to troubleshoot activation rates for free trialists who never become customers, we’ll start with the first with interviewing them as the variable cohort. The control would be its foil — or free trialists who did become customers.
Another example would be gathering insights for product discovery. Depending on business goals, you could consider leveraging insights from paying customers as the control, but variables could be free trialists or deals that never closed, and if you go outside of the realm of known prospects, there’s audience members — people who may not know your brand at all or who have heard of your brand, but never used it before.
When troubleshooting retention and churn, you’d want to compare long-time paying customers who stay (the control) with qualified customers who churned (variable 1) and unqualified customers who churned (variable 2).
In marketing, you’d want to balance new market research of new audiences (variable 1) with both new raving fan customers (variable 2) and long-time die hard raving fan customers (control).
We bring both of these cohorts together so we can determine the following:
What are the patterns between the two (or more) cohorts?
Out of the patterns, which ones produce favorable outcomes?
For unfavorable patterns, can we influence them or improve them to become favorable?
What are the outliers between the two (or more) cohorts?
Out of the outliers, which ones produce favorable outcomes?
For favorable outliers, can we reproduce them to become the pattern?
Patterns can be regarded as circumstances you may want to preserve or keep the same — especially if it produces a favorable outcome. But if it doesn’t produce a favorable outcome, the question becomes, “How can we improve or influence this?”
And for the outliers, you can decide if it’s an outlier to pay attention to or to influence.
Regardless of whether you consider your cohort to be the control or the variable, what matters is that you get BOTH cohorts and not just rely on only one.
If you’re focused on a cohort that zigs, you want to balance it out with the cohort that zags.
Otherwise, you run the risk of succumbing to the One-Body Problem.
Why the One-Body Problem matters in The Work
So now that you’re familiar with what the One-Body Problem is, let’s breakdown why it’s important to consider the cohorts you’re leveraging in any type of qualitative research.
I call it the “One-Body Problem” because it makes me think of Cixin Liu’s series (and later turned Netflix hit), and that makes me smile.
But it’s ultimately rooted in what researchers and strategists call “survivorship bias.”
According to The Decision Lab, “Survivorship bias is a cognitive shortcut that occurs when a successful subgroup is mistaken as the entire group, due to the invisibility of the failure subgroup.”
In tech, and especially in SaaS, survivorship bias is all around us. Think of every unicorn and decacorn that exists and the millions of startups and SaaS companies that lie in its wake over the last quarter-century.
In growth work, survivorship bias emerges most clearly when we think about activation.
We may assume that our activation experiences are performing well because it produces a few paying customers each month, but upon further inspection, we’ve fallen prey to survivorship bias.
We assumed that because those people became customers, then the other trialists weren’t qualified or were a poor fit, somehow. But after conducting a few interviews, it turns out that the survivors were unique in some way and the people who would love to use our product just couldn’t figure it out because we made it too difficult or challenging for regular people to understand.
Survivorship bias is everywhere in the work of growing a SaaS company.
Activation is the easy one, but it’s in also acquisition, retention, and even monetization.
Wherever there is an action or outcome that we want someone to reach, there will always be the survivors and those we leave behind.
To give your brain an extra turn, there’s also reverse-survivorship bias which is the exact opposite: eliminating those who succeeded from the dataset.
That’s actually the example I gave earlier in the post: interviewing only free trialists, but forgetting to interview more recent active-paying customers. We’re essentially biased against people who actually succeed (which presents a gap in understanding).
Either way, whether its survivorship bias or reverse-survivorship bias, it’s all the One-Body Problem.
If we don’t consider its impact, we may fall prey to:
Making changes to onboarding and activation experiences based on our limited view of what creates success and what causes failure
Improperly or inaccurately adjusting messaging and positioning based on a limited understanding of customers and prospects
Designing and building features that don’t appeal to enough of the customer base or attract enough new customers
Failing to accurately troubleshoot poor or slow growth across various customer segments
Making vast false-assumptions about our users and customers that simply don’t reflect back to larger qualified audiences (and therefore making hundreds of decisions based on that limited information)
Creating campaigns that have broad appeal, but don’t generate enough qualified leads (or vice versa depending on the goals of the campaign)
Making big pricing changes that fall flat (or anger the existing customer base)
Generally speaking, the bigger the impact of the problem or the decision you’re trying to make, the more you’ll want to consider the One-Body Problem and if it will result in catastrophe or just a minor, easily correctable blip.
When the One-Body Problem causes product failure
Perhaps one of the most famous examples of the One-Body Problem creating chaos for a company (at least, in America) is New Coke by Coca-Cola.1
In the late 1980s, Coca-Cola suffered from slowly declining sales and growth, so in order to revive the brand and consumer interest, they decided to change its iconic taste and adjust the packaging.
They conducted taste tests with focus groups of new and existing consumers and overall market response revealed that the majority of tasters liked the new taste (it apparently was much sweeter and different notes).
New Coke beat Old Coke by pretty much every standard — even in surveys, taste tests, and focus groups. New Coke won.

But at least 10% of live focus group participants said that they would feel betrayed and upset if Coca-Cola abandoned the old formula in pursuit of the new formula. There were also reports of peer pressure occurring in the focus groups between participants and due to Coca-Cola employees.
Researchers, however, only remained focused on getting feedback about the new formula and failed to explore the loyalty to the classic taste by die-hard Coke fans — a signal they should have picked up on during the focus groups.
There’s also the rollout of the product. The original strategy was for New Coke to rollout city-by-city and replace Old Coke, but they hadn’t considered keeping Old Coke around as a second option in case New Coke didn’t work out.
New Coke suffered from the One-Body Problem — researchers focused on one category of consumer: people who would be open to switching to New Coke.
But they needed both categories: people who wouldn’t be open to adopting New Coke.
Old Coke was brought back within 80 days of launching its would-be successor.
The Two-Body Solution
If you’re about to make a decision or solve a problem and you need to conduct research, make sure you’re considering if the One-Body Problem is going to harm the integrity of your choices.
Adding a second cohort is an easy way to achieve the “Two-Body Solution”; all you need to do is determine which cohort will be your control data set and which will be your variable sets.
Finding the variable is easy — just imagine the mirror-version of whoever you’re focused on based on the context of your problem.
Here are a few quick examples:
Customers 🤝 Non-Customers
Free Trialists 🤝 Active-Paying Customers
Active Users 🤝 Inactive Users
Churned Customers 🤝 Retained Customers
Qualified Churn 🤝 Unqualified Churn
Highly-Aware Prospects 🤝 Unaware Prospects
The list could easily keep going.
Note, however, that these don’t have to represent the demographics or firmagraphics of customers or users, but their status with regards to the relationship they have to your product or to each other.
This is just because I’m assuming you’re already aware of the selection bias that you consider to be appropriate when conducting any form of research (such as specifically choosing to focus on Food bloggers vs. Beauty bloggers).
These segment-based distinctions are pretty easy to make for most folks in product and marketing, for example, and I think a lot of us intuitively do this.
But I want to remind product and marketing leaders of the importance of gathering data from variables AND their controls.
That way, we can operate in a Two-Body System — much more stable, and a helluva lot more maneuverable. 🌎🌞
Source: https://en.wikipedia.org/wiki/New_Coke